GROUP
쿼리 문을 작성할 때 데이터를 그룹화 하기 위해선 꼭 사용해야 하는 개념이다. 데이터를 집계하는 것은 DB에서 상당히 중요하게 다뤄진다. 그렇다면 왜 우리는 그룹화를 하는 것인가? 라고 물으면 집계 함수 계산과 데이터 분석이라고 답할수 있을 거 같다. 우선 전자로 집계 함수에 관해 먼저 살펴보자.
| COUNT | 행의 개수 세기 |
| SUM | 행의 값들의 합 |
| MAX | 행의 값 최댓값 |
| MIN | 행의 값 최솟값 |
| AVG | 행의 값들 평균 |
데이터 분석은 통계적 특징을 분석을 의마할 수 있다. 예를 들어, 온라인 쇼핑몰에서 상품 구매 기록을 분석할 때, 구매자 별로 구매 횟수, 구매 금액 등을 구하여 분석할 수 있다.
GROUP BY 구문을 사용할 때는 다음과 같은 형태를 가진다. 아래 구문에서 GROUP BY에 사용한 컬럼은 SELECT 절에 반드시 포함되어야 한다. 그렇지 않으면 문법 오류가 발생하게 된다.
SELECT 컬럼1, 집계함수(컬럼2)
FROM 테이블명
GROUP BY 컬럼1;실제 예시를 통해 알아보도록 하자.
SELECT *
FROM payment;
위 테이블에서 CUSTOMER_ID 기준으로 그룹화를 해보려고 한다. 그렇게 되면 CUSTOMER_ID 기준으로 모이게 될 것이다. 아래 사진을 보면 이해가 빠르게 될 것이다. (genre 기준으로 그룹화 후 sum(qty) 한 것으로 보인다.)

예시에서는 customer_id로 그룹화 후 행의 개수와 id 별로 amount 합계, 평균치, 최소 값, 최대 값을 출력해보려고 한다.
SELECT CUSTOMER_ID, COUNT(*), SUM(AMOUNT), AVG(AMOUNT), MIN(AMOUNT), MAX(AMOUNT)
FROM PAYMENT
GROUP BY CUSTOMER_ID;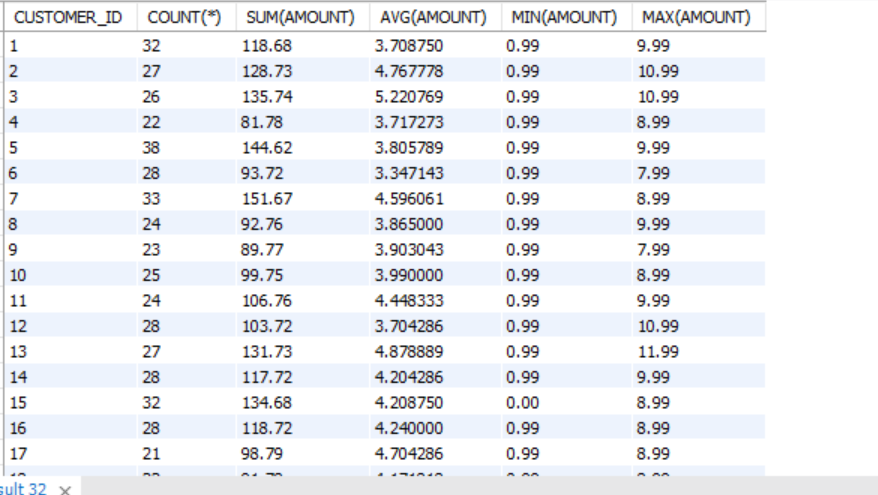
HAVING
그룹화 한 데이터에 대한 조건을 추가할 때 쓰이는 구문이다. WHERE 절과 유사하지만, WHERE 구문은 행 단위로 조건을 적용하고, HAVING 구문은 그룹 단위로 조건을 적용하는데서 차이가 있다. HAVING 위치는 GROUP BY 뒤에 와야 한다.
위 예시를 약간 수정해서 합계가 100 이상이 되는 그룹들만 출력해 보고자 한다.
SELECT CUSTOMER_ID, COUNT(*), SUM(AMOUNT), AVG(AMOUNT), MIN(AMOUNT), MAX(AMOUNT)
FROM PAYMENT
GROUP BY CUSTOMER_ID
HAVING SUM(AMOUNT) >= 100
;
SQL의 GROUP은 문제를 풀때나 실제 프로젝트에서 쿼리를 작성할 때나 항상 나오는 개념이기 때문에 확실히 알아가야 될 개념인 거 같다.
GROUP HAVING COUNT SUM MAX MIN AVG
'Devleop > MySQL' 카테고리의 다른 글
| [MySQL] JOIN : 테이블 합치기 (INNER, LEFT, RIGHT, FULL OUTER) (1) | 2023.05.06 |
|---|---|
| [MySQL] 원하는 문자열 부분 가져오기 (LEFT, MID, RIGHT) (0) | 2023.05.06 |
| [MySQL] CASE 문 : 조건에 따라 값 정하기 (CASE WHEN THEN END) (0) | 2023.05.06 |